Self-Hosted AI: When Your Data Is Too Sensitive for the Cloud
Every AI conversation in business eventually arrives at the same question: where does the data go?
For most applications, the answer is straightforward. You send a prompt to OpenAI or Anthropic’s API, they process it, return a response, and (depending on your agreement) don’t retain it. For internal tools, marketing content, and general productivity, that’s perfectly fine.
But for healthcare records? Legal case files? Sensitive financial data? Government assessments involving vulnerable adults? The answer gets more complicated — and more important.
We’ve been building AI integrations for clients across multiple sectors, and increasingly the conversation isn’t “should we use AI?” but “how do we use AI without sending our most sensitive data to a third party?” That’s what led us to build our own self-hosted AI infrastructure.
What Self-Hosted AI Actually Means
Self-hosted AI means running your own language models on infrastructure you control. Instead of making API calls to OpenAI or Anthropic, you deploy a model — often open-source or fine-tuned from an open-source base — on dedicated GPU hardware within your own environment.
The model runs entirely within your infrastructure. Prompts, responses, training data, and fine-tuning datasets never leave your network. You control the hardware, the model weights, the data pipeline, and the output.
This isn’t a new concept, but it’s become genuinely practical in the last 18 months. The quality of open-source models has improved dramatically, GPU availability has stabilised, and the tooling for fine-tuning and deploying models has matured to the point where a competent engineering team can build production-grade self-hosted AI systems.
A Real Example: Ask HRMNY
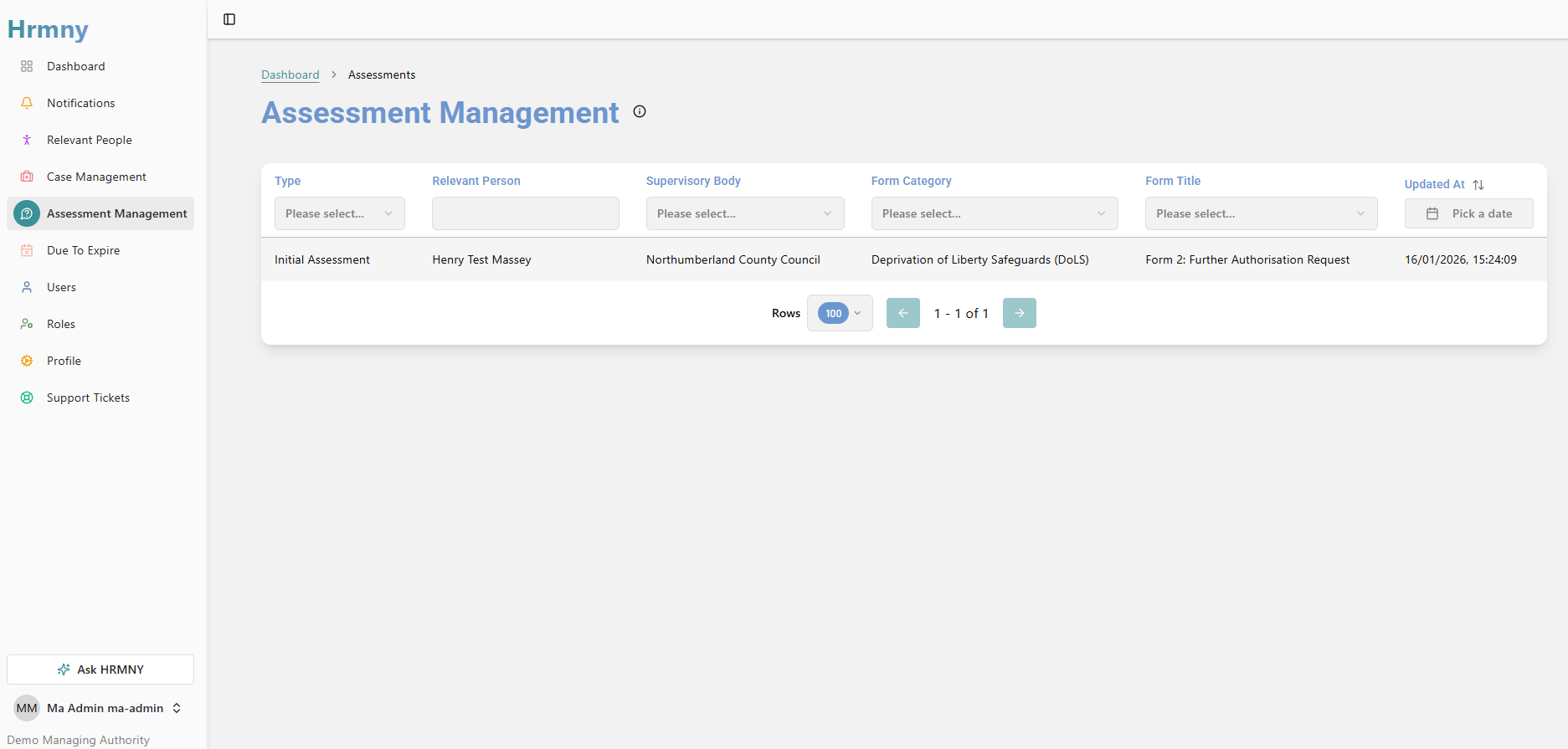
Our most significant self-hosted AI deployment is inside HRMNY — a statutory health and social care assessment platform we built for managing Deprivation of Liberty Safeguards (DoLS), Care Act assessments, and mental capacity evaluations.
HRMNY handles some of the most sensitive data imaginable: detailed assessments of vulnerable adults, clinical observations, legal capacity determinations, and safeguarding information. Sending any of this to a third-party AI provider would be a non-starter — both ethically and legally.
So we built “Ask HRMNY” — a self-hosted AI assistant trained specifically on:
- Adult care legislation and statutory guidance
- DoLS procedures and best practice documentation
- Mental Capacity Act frameworks and case law
- Assessment form structures and completion standards
The AI provides field-level quality assurance on assessment documentation in real time. When an assessor is completing a DoLS form, Ask HRMNY can flag where statutory language is missing, where reasoning doesn’t meet the legal threshold, or where additional evidence is needed — all without any patient data ever leaving the infrastructure.
The result? HRMNY estimates it reduces Stage One DoLS completion time from an average of 150 days to under one hour, with active case time of approximately 25.5 minutes per case.
The Case For Self-Hosted AI
1. Data Sovereignty
This is the big one. When you self-host, your data stays yours. No third-party data processing agreements. No risk of your training data being incorporated into a provider’s foundation model. No dependency on another company’s privacy policy — which can change at any time.
For regulated industries — healthcare, legal, government, financial services — this isn’t a preference. It’s often a hard requirement.
2. Domain Expertise
A general-purpose model like GPT-4 or Claude knows a bit about everything. A fine-tuned model trained on your domain data knows a lot about your specific area. For HRMNY, our model understands the nuances of DoLS legislation at a depth that no general model can match — because it’s been trained on thousands of real assessment documents and the statutory guidance that governs them.
This isn’t about the model being “smarter.” It’s about it being specifically knowledgeable about the domain where you need it to perform.
3. Predictable Costs at Scale
Cloud AI pricing is per-token. Every API call costs money, and for high-volume applications those costs add up fast. Self-hosted models have a fixed infrastructure cost — once your GPU hardware is running, whether you process 100 requests or 100,000 requests, the cost is the same.
For applications with heavy AI usage — think thousands of assessments per month, each requiring multiple AI interactions — the economics tilt decisively towards self-hosted within months.
4. Availability and Independence
When OpenAI has an outage (and they do), every application relying on their API goes down with them. Self-hosted models run on your infrastructure, with your uptime guarantees. For mission-critical systems in healthcare or legal compliance, this independence is essential.
5. Full Control
You control the model version, the fine-tuning data, the system prompts, the output formatting, the inference parameters, and the upgrade schedule. No surprise model changes. No deprecated endpoints. No sudden pricing adjustments. Your AI behaves predictably because you control every variable.
The Honest Trade-Offs
We believe in giving clients the full picture. Self-hosted AI is powerful, but it’s not free of trade-offs.
Infrastructure Investment
You need GPU hardware — either physical servers or dedicated cloud GPU instances. This is a meaningful upfront cost. A single NVIDIA A100 GPU costs thousands of pounds, and production deployments typically need redundancy. The cloud GPU alternative (AWS, Azure, dedicated GPU providers) removes the hardware burden but adds ongoing compute costs that can be significant.
Capability Ceiling
The largest frontier models (GPT-4, Claude Opus) are enormous — hundreds of billions of parameters requiring massive compute clusters to run. Self-hosted models are typically smaller: 7B, 13B, or 70B parameters. They can be exceptional at their trained domain, but they won’t match the general-knowledge breadth of the largest cloud models. This is fine when you need domain expertise; less fine when you need broad reasoning across unfamiliar topics.
Ongoing Maintenance
Models need periodic retraining as your data evolves and regulations change. Infrastructure needs monitoring, patching, and scaling. This is an ongoing operational commitment, not a deploy-and-forget situation. You need either in-house ML operations expertise or a partner (like us) who provides it.
Development Complexity
Building a production self-hosted AI system involves model selection, fine-tuning pipelines, vector databases for RAG, embedding generation, inference optimisation, and monitoring. It’s meaningfully more complex than calling a cloud API endpoint. The engineering investment is higher — but so is the control and specificity of the result.
Our Recommendation: The Hybrid Approach
We rarely recommend going all-in on either self-hosted or cloud AI. The smartest strategy is hybrid:
- Self-hosted for sensitive data processing, domain-specific tasks, and high-volume operations where cost predictability matters
- Cloud APIs for general-purpose tasks, creative content, broad knowledge queries, and low-volume use cases where the frontier models’ breadth genuinely adds value
For HRMNY, the assessment quality AI is entirely self-hosted — it handles sensitive patient data and needs deep statutory knowledge. But the platform’s general search and content assistance features use cloud APIs, because those tasks benefit from larger models and don’t involve regulated data.
This isn’t a compromise. It’s using the right tool for each specific job.
Is Self-Hosted AI Right for You?
Consider self-hosted AI if:
- You handle sensitive data that can’t leave your infrastructure (healthcare, legal, government, financial)
- You need AI that deeply understands your specific domain — not just general knowledge
- You process high volumes of AI requests where per-token pricing becomes expensive
- You operate in a regulated industry with strict data residency requirements
- You need guaranteed availability independent of third-party providers
Stick with cloud APIs if:
- Your data isn’t particularly sensitive and standard DPAs are sufficient
- You need broad general knowledge rather than deep domain expertise
- Your AI usage is low-volume and cost isn’t a concern at current API pricing
- You want the simplest possible integration with minimal infrastructure overhead
If you’re exploring AI for a project that handles sensitive data — or you’re currently using cloud APIs but uncomfortable with where your data goes — get in touch. We’ve done this in production with real regulatory requirements, and we’re happy to talk through what it would look like for your specific situation.